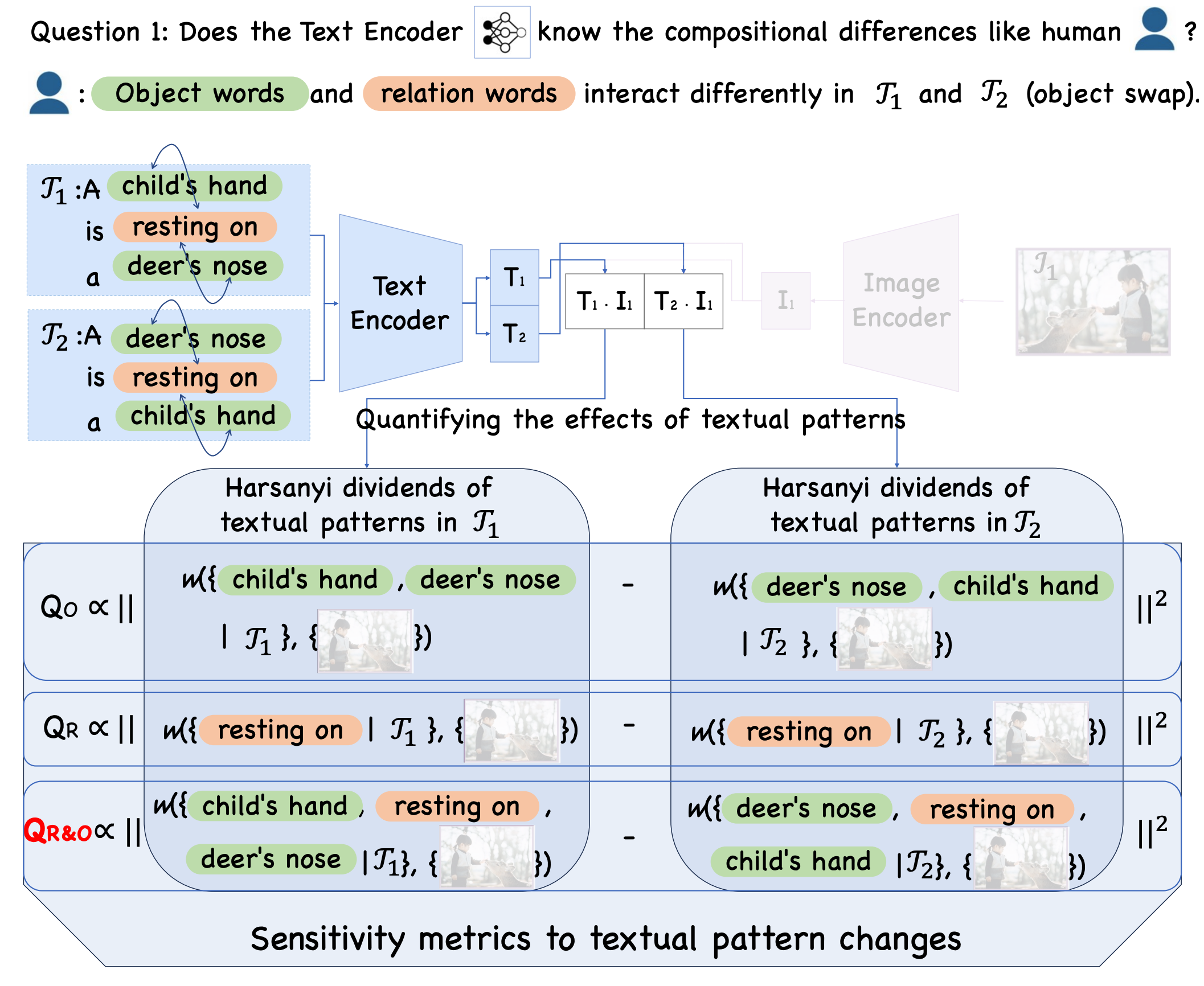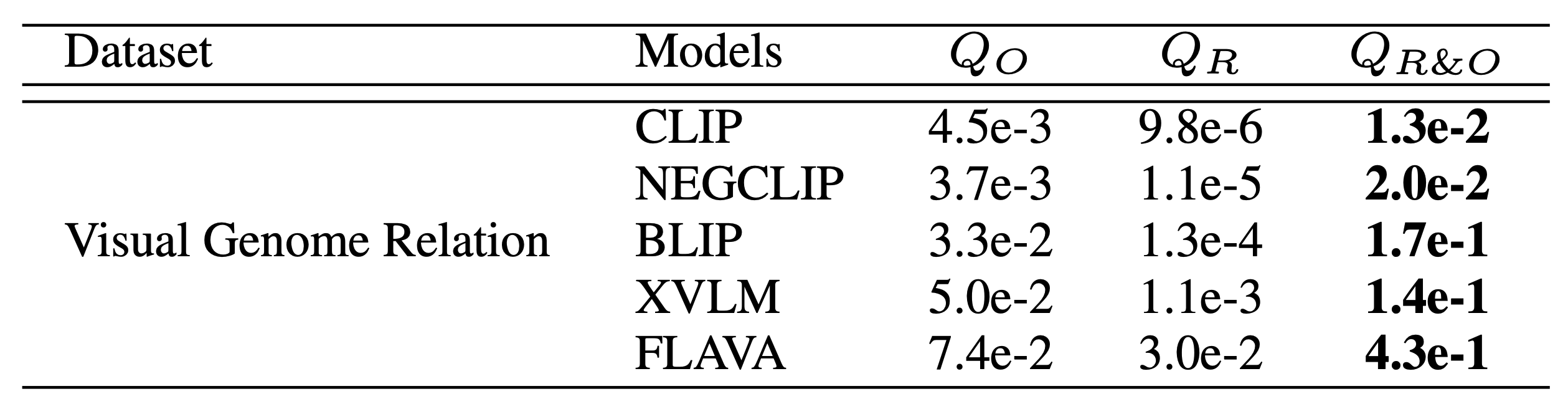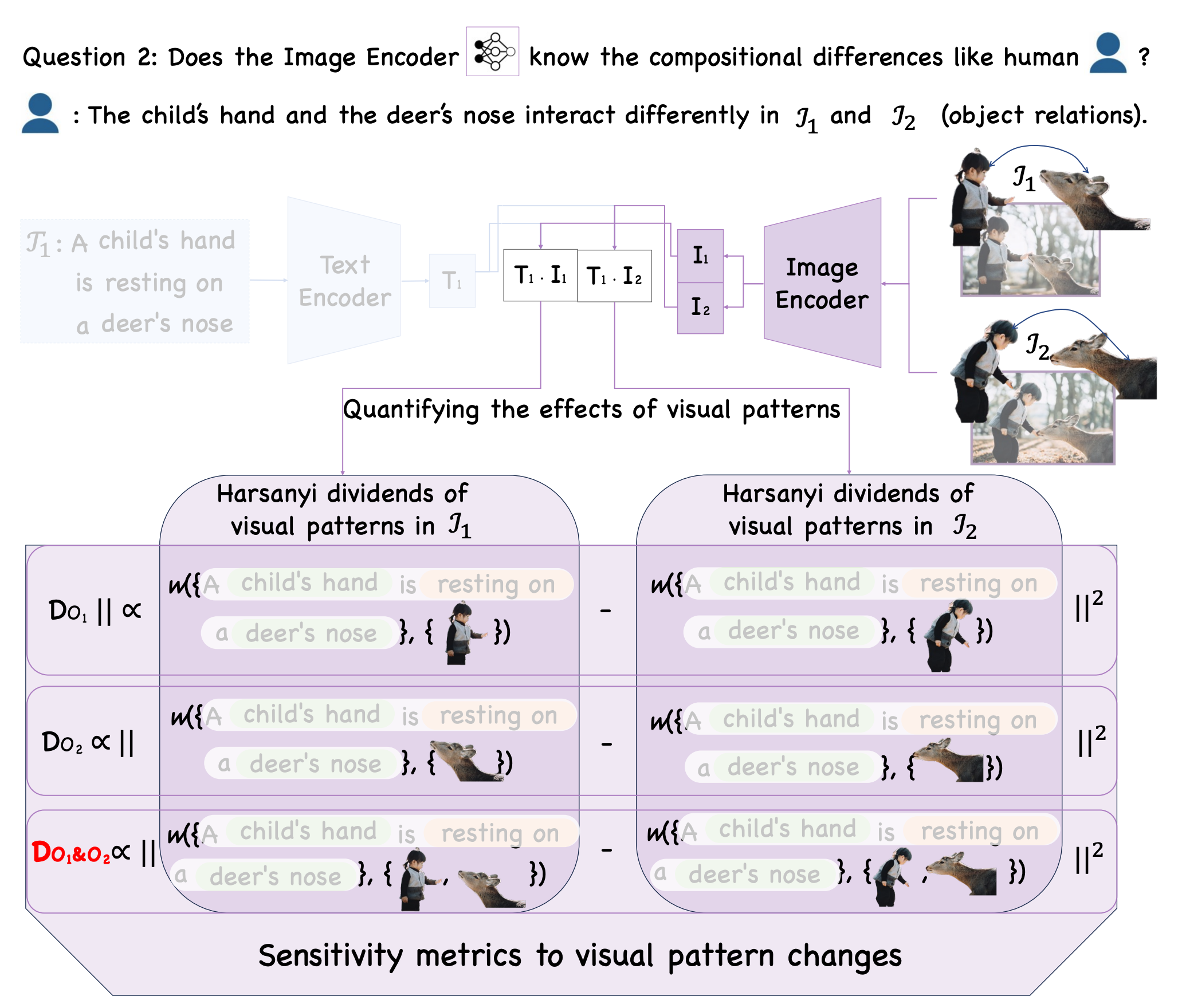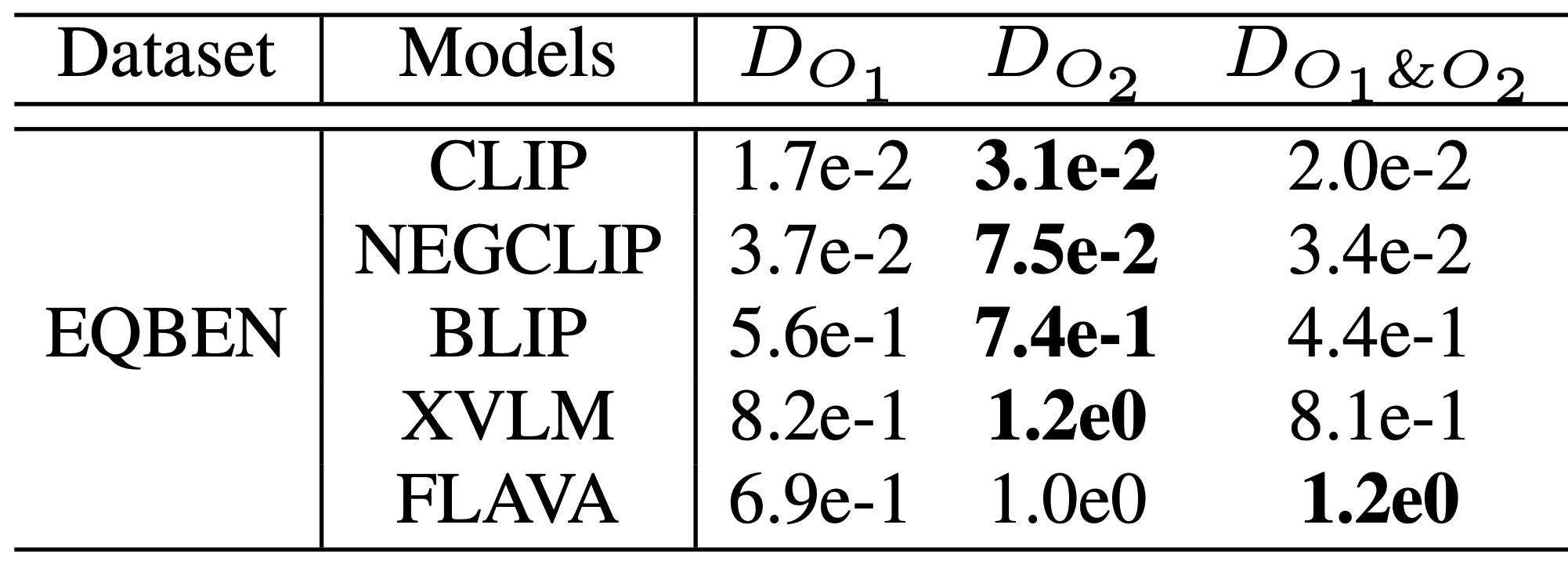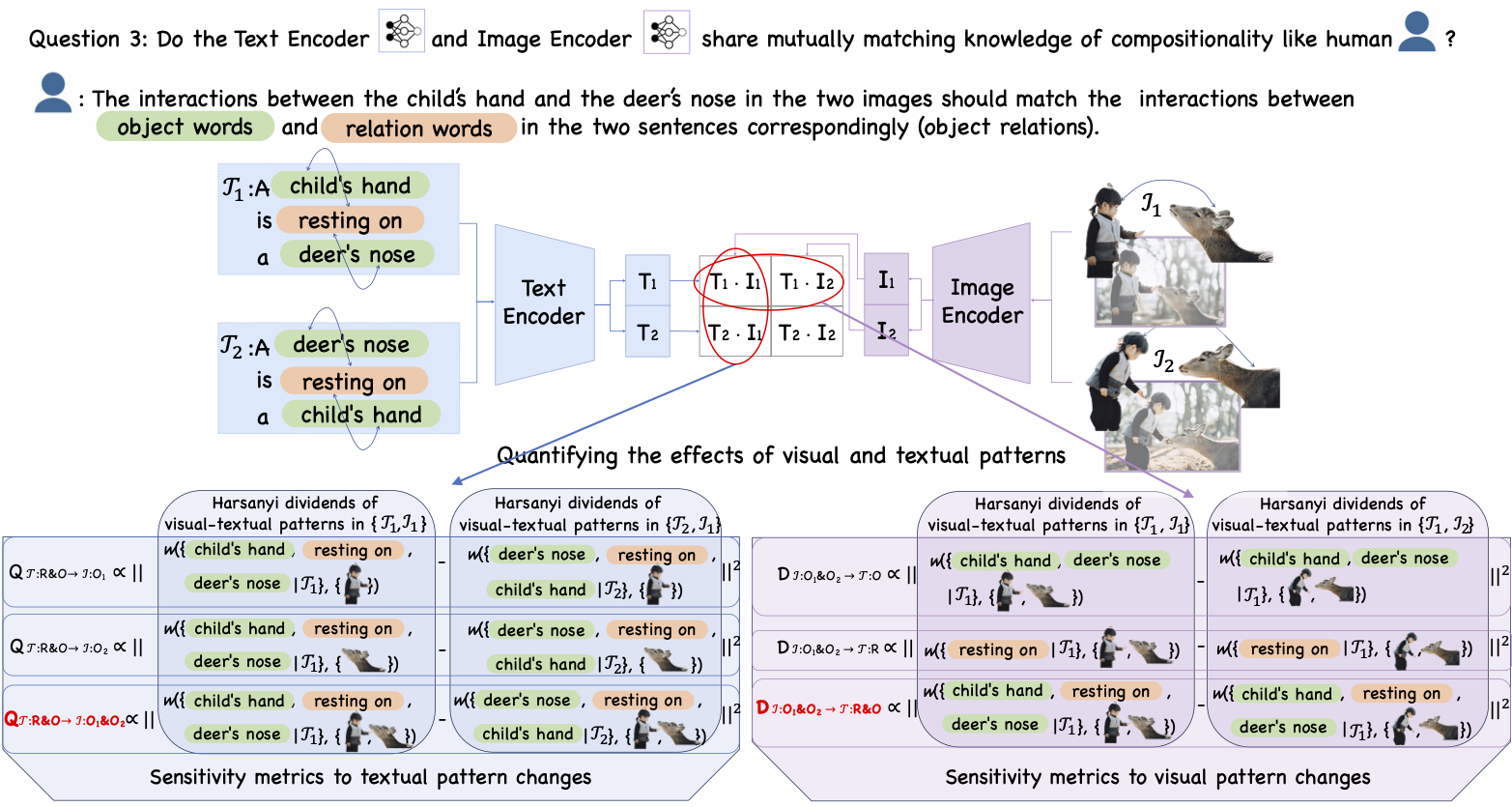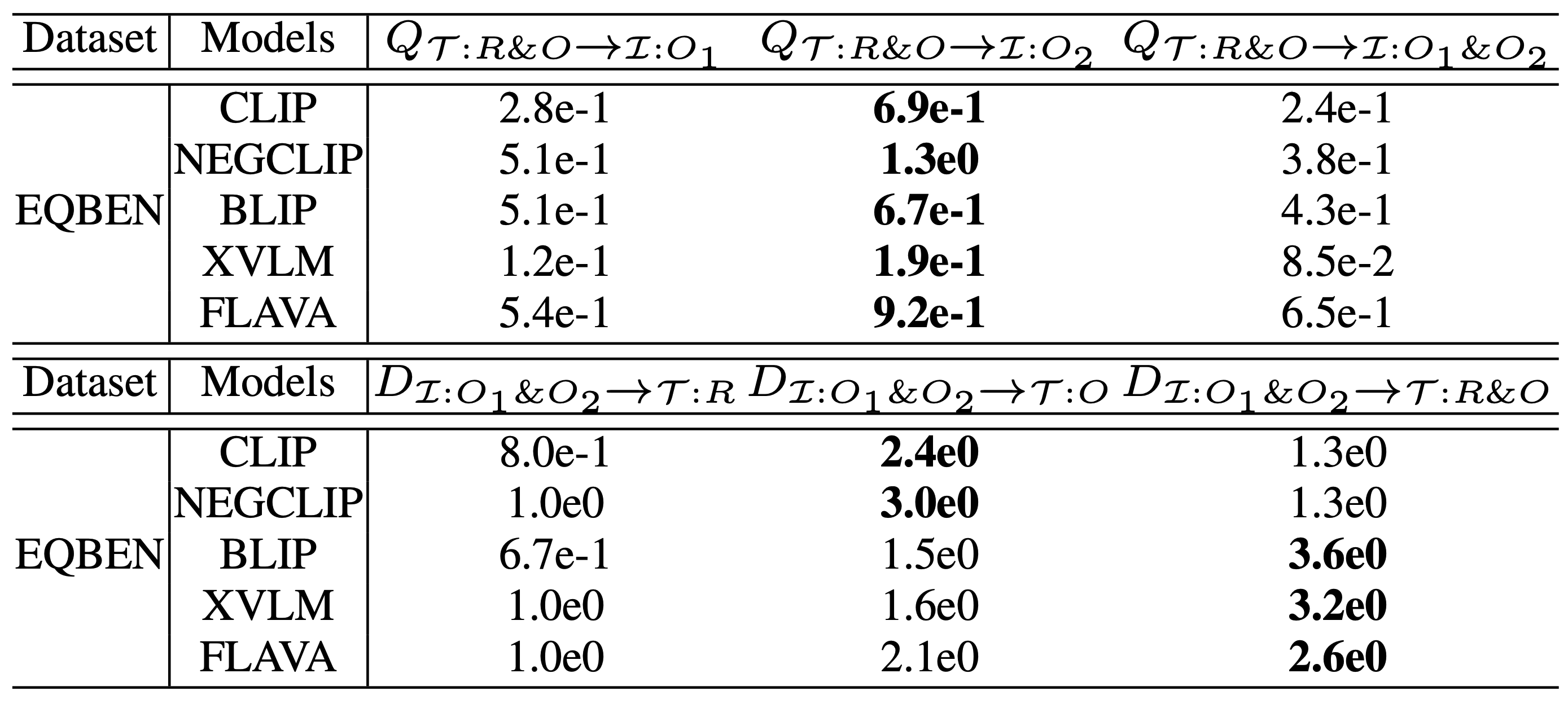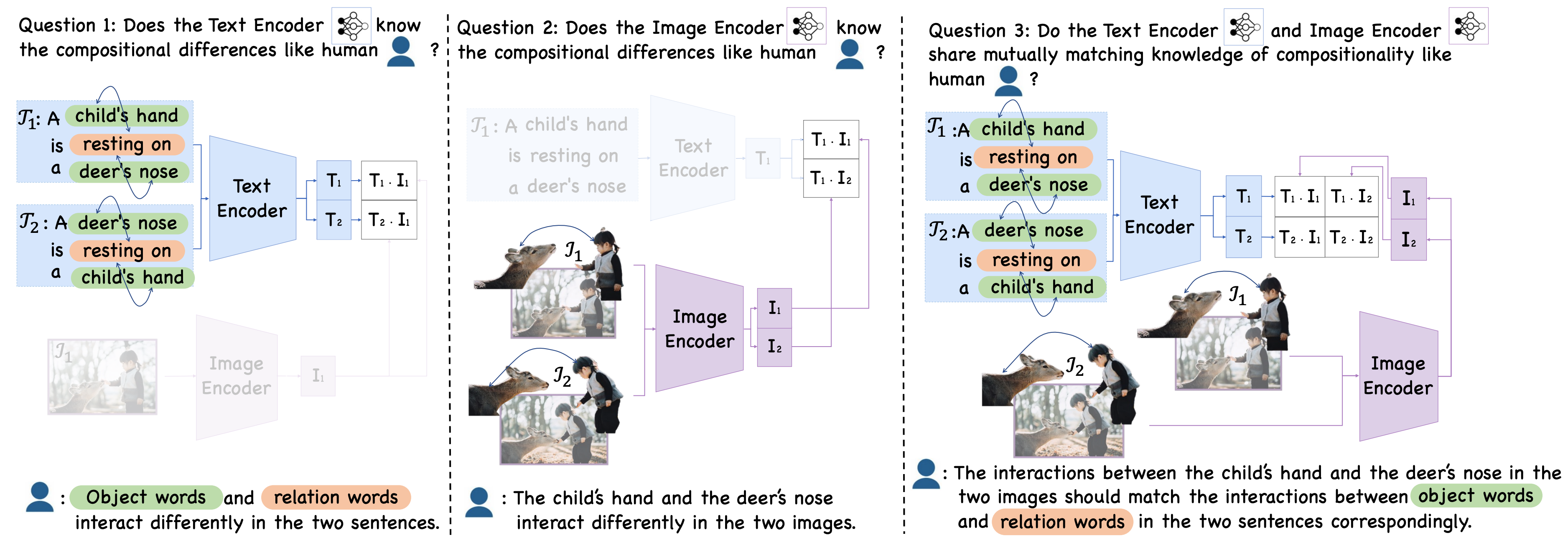
Diagnosing the compositional reasoning capabilities of Vision Language Models (VLMs). In this paper, we systematically analyze the potential causes for the poor compositional performance of VLMs from each unimodal separately and then multimodal jointly. In this way, three insights are obtained and validated correspondingly.